

 会员登录
会员登录
在 WINDOWS 中设置kaspa节点
解压缩下载的存档
将下载的存档解压缩到适合您的任何位置。
在下面的文本中,将针对将文件解压缩到文件夹中的情况编写所有示例。如果将存档解压缩到另一个文件夹,请将示例和说明中的此路径替换为您自己的路径。此外,还给出了Microsoft Windows的所有解释。C:\Kaspa\
解压后,文件夹中将有 5 个文件:、、 和 ,您需要的文件是 .稍后您还需要一个用于创建钱包,请参阅相关文章。不要使用:这是一个参考矿工实现,还有更有效的,参见挖矿。C:\Kaspa\genkeypair.exekaspactl.exekaspad.exekaspaminer.exekaspawallet.exekaspad.exekaspawallet.exekaspaminer.exe
创建批处理文件
您可以立即运行,但由于它有时会崩溃,因此最好通过创建 Windows 批处理执行 () 文件将其置于无限循环中。要创建它,请在文件夹窗口中单击鼠标右键,选择并选择,然后将创建的文件重命名为 .确保 Windows 不会隐藏文件扩展名,否则您最终会得到一个不知情的文件,这不是您需要的。kaspad.exe.batC:\Kaspa\"Create->New text document"kaspad.batkaspad.bat.txt
使用 Windows 记事本打开此文件,并在其中添加以下行:
:xxx
kaspad.exe --utxoindex
goto xxx
这样,当节点崩溃时,它将自动重新启动。从现在开始,您可以随时通过双击该文件来启动该节点。尽管您应该在执行此操作之前进一步阅读。kaspad.bat
该标志使 kaspad 计算每个地址的余额并缓存它们以供钱包操作进一步使用。如果你不需要查看余额和发送硬币,而只挖矿到节点,你可以省略这个参数。--utxoindex
默认文件夹
Kaspad 将其数据(DAG 数据库、日志文件、配置文件、内存转储)保存在文件夹中。初始同步过程后,此文件夹的大小约为 3 GB,大约一个月后将增长到 30 GB。%localappdata%\Kaspad
如果你对此感到满意,就什么都不做。
如果希望将此数据存储在另一个位置(例如,系统光盘上的存储空间有限),请使用(或相同的)命令行参数以及其他参数。例如,如果希望将数据存储在文件夹中,则命令行应如下所示。Kaspad 目前不需要快速 HDD/SSD,因此您可以轻松地将其文件设置为存储在大容量低速 HDD 上。--appdir-bc:\kaspa_datakaspad.exe --appdir c:\kaspa_data --utxoindex
Bootstrap 数据库快照
如今,使用数据库引导程序几乎从来都不合理,因为从头开始同步的过程通常需要大约 30 分钟。但是,如果您仍然觉得它会随着引导程序而更快地结束(如果您有一台非常旧的 PC、不到 8 GB 的 RAM 或互联网连接速度非常慢),您可以从 http://www.kaspadbase.com/ 下载 kaspad 数据库的存档(Windows 和 Linux 版本存档都可以在任何操作系统中使用, 因为 kaspad 的文件结构是跨平台的),在 Kaspa Discord 服务器的 #datadir_exchange 频道中查找最新的存档。
解压缩存档,使其文件夹进入电脑的文件夹或您在上一步中选择的任何文件夹。如果您以前从未启动过kaspad,也从未创建过该文件夹,则必须先手动创建它。kaspa-mainnet%localappdata%\Kaspad
如果目标文件夹中已经有一个文件夹,强烈建议您先将其删除,以避免文件因不同的 kaspad 启动而混乱。Kaspad DB 引擎肯定不会喜欢这种混乱,并且可能会崩溃。kaspa-mainnet
设置特殊参数
如果您知道 LAN 中某个工作节点的 IP,并希望向 kaspad 提示如何使用该节点作为数据源,请使用命令行参数和其他参数。--addpeer <other node's IP address>
如果您希望某个节点成为 kaspad 的唯一数据源,请使用命令行参数。--connect <other node's IP address>
您可以通过使用命令行参数运行 kaspad 来查看一整套其他可用参数及其描述,有时还可以看到默认值。要查看有关某些命令的更详细帮助,您可以运行 。--helpkaspad <that command> --help
开始
双击您的文件。不要以管理员身份运行它,在这种情况下,由于隐式工作目录更改,可能会失败。以普通用户身份运行它。kaspad.bat
您将看到一个控制台(文本)窗口,其中包含 kaspad 的执行日志。
同步阶段
同步过程通常包括 2 个短同步阶段和 3 个大同步阶段:处理修剪点证明(一个短同步)、处理标头、获取修剪点 UTXO 集(另一个短同步)、处理块和构建 DAG。这是为了完全从头开始同步;如果您使用的是数据库快照,则与实际 DAG 状态相比,根据快照数据的状态,阶段可能会减少。
要熟悉日志内容的一般内容,请查看日志内容说明部分。
加工修剪点证明
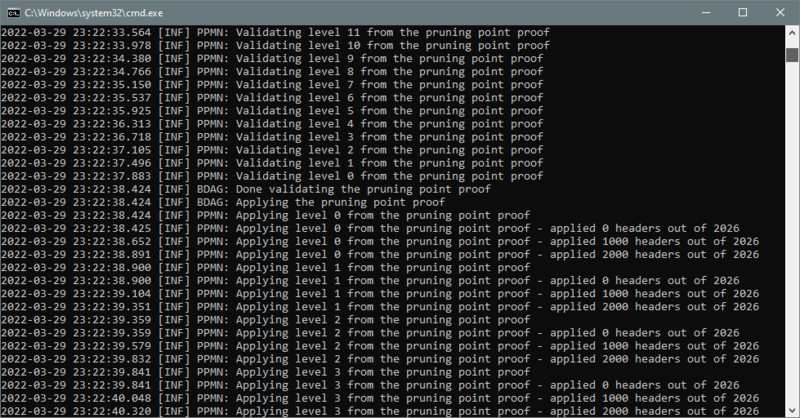 “验证和应用修剪点证明”阶段截图
“验证和应用修剪点证明”阶段截图
修剪点证明处理包括证明的下载、验证和应用子阶段。通常只需不到几分钟的时间。
处理标头
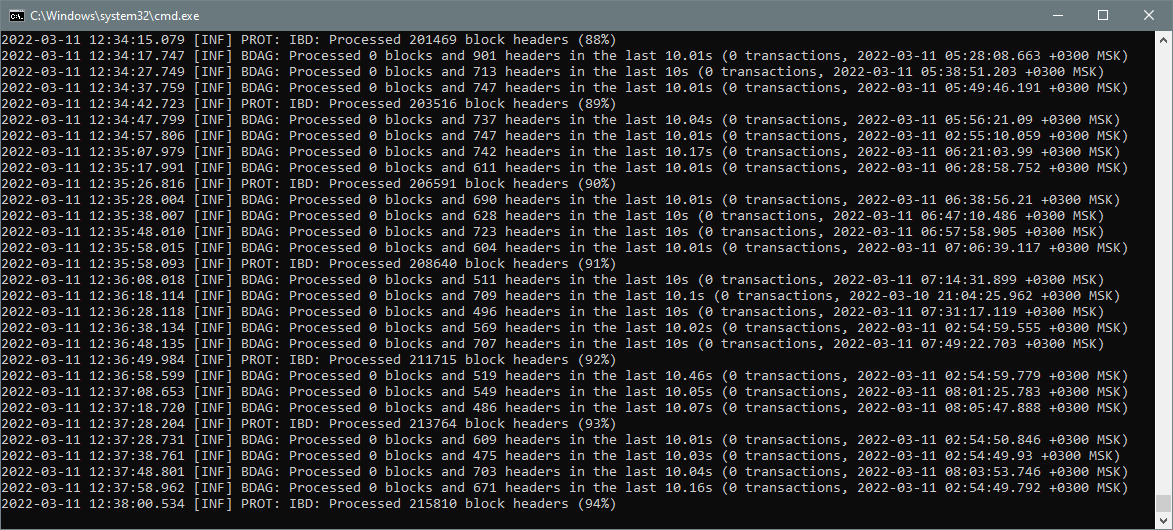 “处理标头”阶段屏幕截图
“处理标头”阶段屏幕截图
在完成一个修剪点证明处理后,将开始一个相对较长的处理标题阶段。您将看到块标头是从 3 天前到当前时间处理的。当前处理标头的时间(即创建这些标头的相应块的时间)可以在每个“”行的最后一部分看到。您还将看到一行“”,表示总阶段完成的下一个百分比。Processed 0 blocks and X headers[INF] PROT: IBD: Processed XXX block headers (N%)
此阶段是最长的阶段,通常需要 20 分钟到 2 小时,具体取决于前 3 天的 DAG 结构以及存储设备的速度特征。
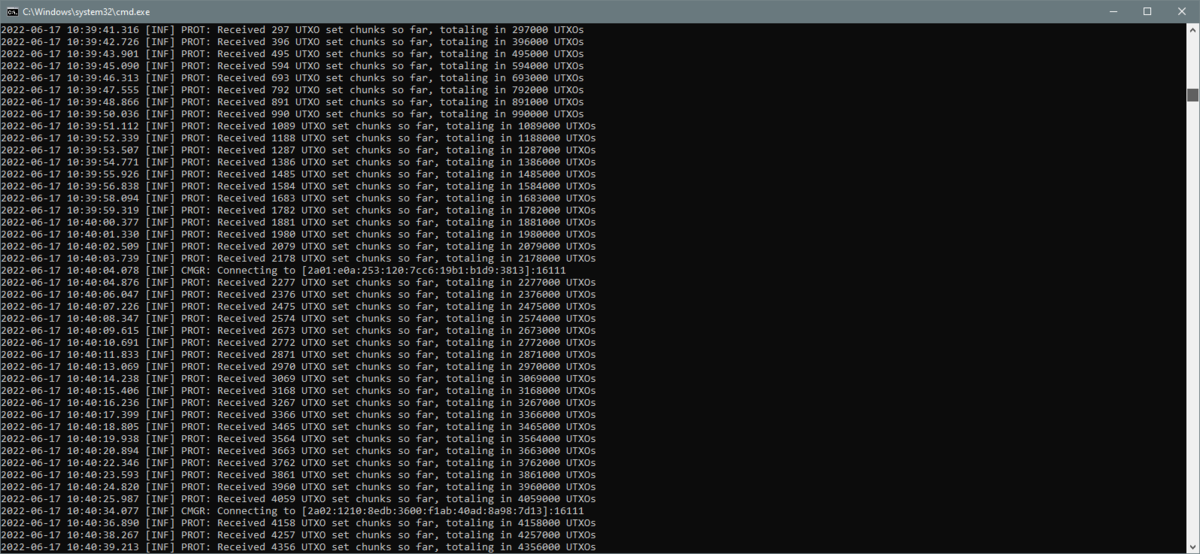 “获取修剪点 UTXO 集”阶段截图
“获取修剪点 UTXO 集”阶段截图
获取修剪点 UTXO
处理标头后,节点会收集与修剪点相对应的 UTXO集。此阶段由“”行表示,大约需要几分钟,以字符串“”结尾。[INF] PROT: Received XXX UTXO set chunks so far, totaling in YYY UTXOs[INF] PROT: Finished receiving the UTXO set. Total UTXOs: ZZZ
此阶段大约需要一分钟。
处理块
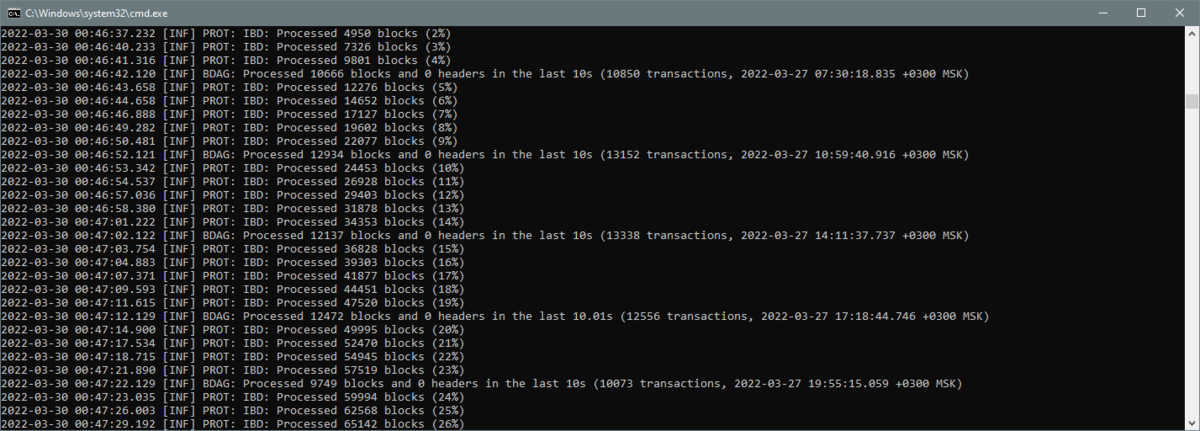 “处理块”阶段截图
“处理块”阶段截图
获取 UTXO 集后,将开始另一个更长的阶段,处理与先前收到的区块头相对应的适当区块体。您现在将看到该块是从 3 天前到当前时间处理的。当前正在处理的块的时间(即创建这些块的时间)可以在每个“”行的最后一部分看到。Processed X blocks and 0 headers
这个阶段通常需要 5 到 20 分钟。
解析虚拟
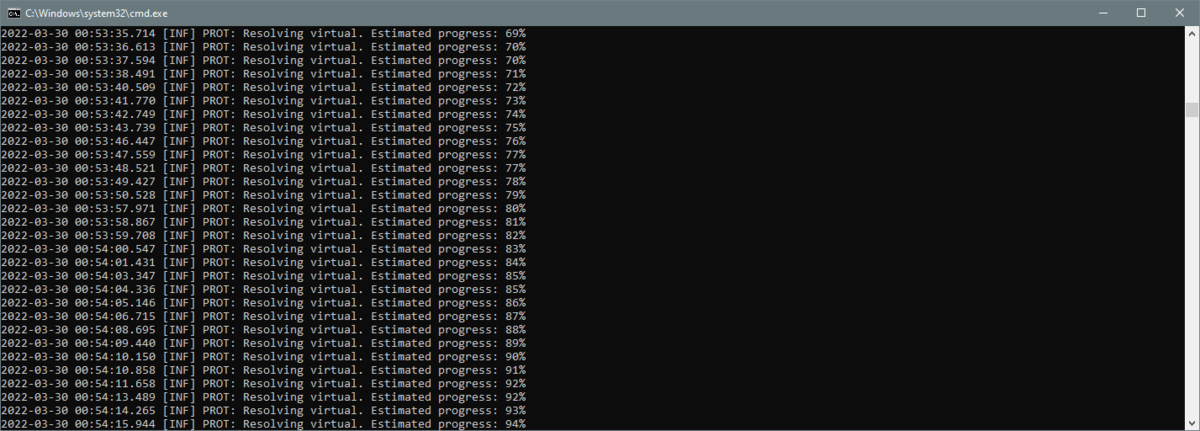 “解析虚拟”阶段截图
“解析虚拟”阶段截图
这个阶段是最后一个阶段,也是一个很短的阶段,最长只需要几分钟。您将看到多个“”行。[INF] PROT: Resolving virtual. Estimated progress: XX%
可能的新一轮
由于同步过程需要大量时间,但 DAG 一直在进一步构建,因此在同步过程结束时,另一组数据将准备就绪,必须对其进行处理才能使节点完全同步。因此,最后 3 个阶段将再次发生,但这次要快得多,因为只需要处理同步过程花费的 20 分钟到 2 小时的数据。然后也许再一次,取决于 PC 的 CPU 功率和 RAM 大小。
节点已同步
当您在节点的窗口输出中看到消息流 “” 时,这意味着该节点已完全同步。[INF] PROT: Accepted block XXX via relay
正常操作
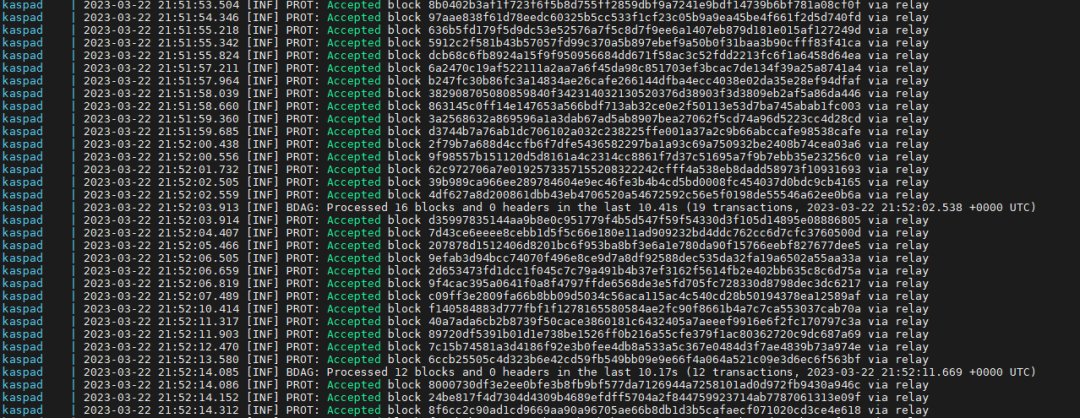 “正常节点操作”截图
“正常节点操作”截图
通常,node 的大部分输出都由行 “” 组成,但您会时不时地看到诸如 “”“、”“、”“、”“、”“ 甚至 ”“、 ”“ 和 ”“ 之类的行。这一切都是节点的正常操作方式,并且基于 DAG 的分布式性质,其中数据有时会以意想不到的顺序出现,但节点必须处理它。Accepted block XXX via relayIgnoring duplicate block XXXReceived a block with missing parents, adding to orphan pool: XXXUnorphaned block XXXBlock XXX has X missing ancestors. Adding them to the invs queueIDBResolving virtualIDB finished successfully
 |
 |
 |
 |
 |
 |
 |
 |
| 感动 | 同情 | 无聊 | 愤怒 | 搞笑 | 难过 | 高兴 | 路过 |
相关文章
-
没有相关内容